분류 모델은 데이터를 분류하는 방법을 학습한다. 분류 모델은 크게 이진 분류(Binary Classification)와 다중 분류(Multi Classification)로 나뉜다.
- 이진 분류(Binary Classification)는 입력값에 따라 모델이 분류한 카테고리가 두 가지인 분류 알고리즘. 주로 어떤 대상에 대한 규칙이 참(True)인지 거짓(False)인지를 분류하는데 쓰인다.
- ex. 암 종양을 분류하는 모델 → 어떤 종양을 입력으로 받았을 때 이 종양이 암 종양인지(True) 암 종양이 아닌지(False)
- 다중 분류(Multi Classification)은 입력값에 따라 모델이 분류한 카테고리가 세 가지 이상인 분류 알고리즘입니다.
- ex. 숫자 손글씨를 분류하는 모델(0~9까지 10개의 카테고리)
예를 들어 두 분류를 살펴보다면, 숫자는 0부터 9까지 총 10개가 있을 때, 만일 손으로 쓴 숫자 데이터 세트에 대하여
입력으로 받은 숫자 사진이 0인지 아닌지 분류하는 것은 이진 분류 모델을, 입력으로 받은 숫자 사진이 0부터 9 중 어떤 숫자인지 분류하는 것은 다중 분류 모델을 사용한다.
1. 이진 분류 (Binary Classification)
로지스틱 회귀 (Logistic Regression)

시그모이드 함수
로지스틱 함수는 활성화함수로 시그모이드 함수를 사용한다. (시그모이드 함수는 모든 z값에 대해 0과 1사이의 함숫값을 갖는 함수)
로지스틱 회귀 모델은 입력값과 가중치를 곱해 나온 값(z)을 활성화 함수에 대입하고, 활성화 함수를 통과한 값(a)이 임계치 이상이면 참(True)을, 이하면 거짓(False)을 반환한다. 활성화 함수를 시그모이드 함수로 사용하면 활성화 함수를 통과한 값(a)이 0부터 1까지의 값을 갖기 때문에 이를 확률처럼 해석할 수 있게 되고, 만일 '참(True) 일 확률이 60%(0.6)인 경우에 대해서만 참(True)으로 분류'하는 모델을 만든다면 임계 함수에서의 임계치만 0.6으로 수정해 주면 된다.
2. 모델의 성능 평가
confusion matrix
TP : 실제 Positive인 정답을 Positive라고 예측 (True)
TN : 실제 Negative인 정답을 Negative라고 예측 (True)
FP : 실제 Positive인 정답을 Negative라고 예측 (False)
FN : 실제 Negative인 정답을 Positive라고 예측 (False)
Accuracy
Accuracy는 ‘실제 데이터에서 예측 데이터가 얼마나 같은지’를 판단하는 단순한 지표다.
정확도를 사용할 때 주의해야 할 점은 이진 분류인 데이터는 머신러닝 모델의 성능을 정확하게 판별하지 못하기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않는다는 것이다. 단편적으로 Accuracy만 봤을 때 좋은 값이 도출되지만, 실제로 부정인 것은 예측을 잘 못하기 때문에 좋은 모델이라고 하기 어렵다는 것인데, 이러한 결과는 데이터의 불균형으로 인해 발생한다.
예를 들어 9명의 건강한 사람과 1명의 질병을 가진 사람이 있다면, Accuracy는 90%가 된다.
그러나 정확도가 높다고 해서 다 좋은 모델은 아니다.
이 경우의 머신러닝 모델은 모든 사람을 건강한 사람으로 예측한다고 해도 Accuracy는 90%가 되기 때문에 결국 정확도는 90%이지만, 이 모델은 질병을 가진 사람을 건강한 사람으로 분류하기도 하기 때문에 좋은 모델이 아니게 되는 것이다.
따라서 아래에 나오는 다른 여러 지표들과 함께 사용해야 한다.
Precision/Recall

보통 recall이 precision보다 상대적으로 중요한 업무가 많지만, precision이 더 중요한 지표인 경우도 있다.
- Recall이 중요한 케이스 : 암 검출, 금융사기 검출 같은 Task에서는 실제로 Positive인 얘들을 Negative로 예측하면 안된다.
- Precision이 중요한 케이스 : 스팸 검출 같은 Task에서는 실제로 Negative인 얘들을 Positive로 예측하면 안된다.
Precision/Recall Trade-off
Precision과 Recall은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉬운데, 이를 Precision/Recall Trade-off라 부른다.
Precision과 Recall의 Trade-off를 결정하는 수치는 Threshold인데, Threshold는 Positive 예측값을 결정하는 확률의 기준이 된다. 보통 이진 분류의 경우 확률이 0.5 초과면 Positive로, 0.5 이하면 Negative로 예측한다.
- Threshold를 낮추면, Positive로 예측하는 값이 더 많아지게 되니 Precision은 감소하고, Recall은 증가하고, Threshold를 높이면, Positive로 예측하는 값이 더 적어지게 되니 Precision은 증가하고, Recall은 감소하게 된다.


F1 Score
F1 Score는 Precision과 Recall을 조화평균한 지표. Precision과 Recall이 어느 한 쪽으로 치우치지 않을 때 상대적으로 높은 값을 가진다.

3. ROC AUC
ROC curve

TPR : True Positive Rate, 실제 값인 Positive가 정확히 예측되어야 하는 수준
TNR : True Negative Rate, 실제 값인 Negative가 정확히 예측되어야 하는 수준
FPR : False Positive Rate, FPR = 1-TNR로 구함
ROC-AUC score
결국 분류의 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC(Area Under Curve).
AUC(Area Under Curve) 값은 ROC 곡선 밑의 면적을 구한 것으로, 1에 가까울수록 좋은 수치.
4. 다중 분류 (Multiclass Classification)

로지스틱 회귀의 경우 참(True) 또는 거짓(False)을 판별하기 때문에 출력 값이 하나였지만, 다중 분류 모델은 타깃의 종류가 여러 개이기 때문에 출력 값도 여러 개. 각각의 출력 값은 그에 대응하는 타깃과 매칭 될 확률을 나타낸다.
로지스틱 회귀에서는 선형 방정식을 통과한 값을 sigmoid함수를 이용하여 가공했으나, 다중 분류는 softmax함수를 사용한다.
마지막으로 로지스틱 회귀에서는 마지막에 나온 a값이 임계치를 넘는지에 따라 참과 거짓을 판별하기 위해 threshold function을 이용했지만 다중 분류 모델에서는 함수는 one-hot encoding 기법을 사용하고 있습니다.
softmax 함수
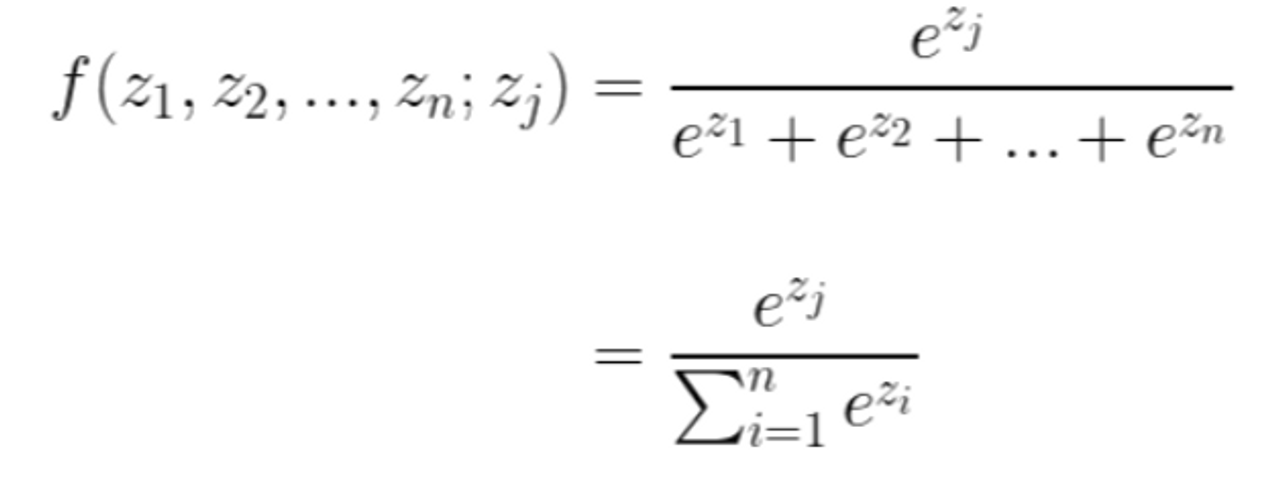
Softmax 함수는 시그모이드 함수를 일반화한 함수로, 시그모이드 함수처럼 결과값을 확률처럼 해석할 수 있게 해 준다. 즉, 입력값에 따라 중구난방으로 튀는 값들을 0부터 1 사이의 숫자들로 정규화시켜주고, 또한 위의 수식을 보면 알 수 있듯이 출력으로 나온 값들의 합이 1이므로 확률처럼 서로 다른 입력값에 대해서도 비교할 수 있게 해 준다.

One-hot encoding
softmax함수를 통과한 값들 중 가장 높은 값에 대응하는 클래스가 바로 모델의 예측값이 된다. 다중 분류 모델은 single-label classification이므로 하나의 클래스에만 대응될 수 있다. 따라서 다중 분류 모델은 softmax를 통과한 값 중 가장 높은 값을 1로 남겨두고, 나머지 값들은 모두 0으로 만든다.
Reference

Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow (2판)
댓글