
데이터 전처리 : 분석에 적합하게 데이터를 가공하는 작업
<pandas 패키지 - 데이터 가공 함수>
| 함수 | 기능 |
| query( ) | 행 추출 |
| df( ) | 열(변수) 추출 |
| sort_values( ) | 정렬 |
| groupby( ) | 집단별로 나누기 |
| assign( ) | 변수 추가 |
| agg( ) | 통계치 구하기 |
| merge( ) | 데이터 합치기(열) |
| concat( ) | 데이터 합치기(행) |
조건에 맞는 데이터 추출하기
실습에 활용한 데이터는 exam.csv 파일이다. id(번호), nclass(반), math(수학 점수), english(영어 점수), science(과학 점수) 변수들로 이루어져있다.
import pandas as pd
exam = pd.read_csv('exam.csv')
exam
# nclass가 1인 경우만 추출
exam.query('nclass == 1')query( ) - '같다'를 의미하는 조건 입력 시, 등호 = 를 두 번 반복한다.
# nclass가 1이 아닌 경우
exam.query('nclass != 1')변수가 특정 값이 '아닌 경우'에 해당하는 데이터를 추출하기 위해서는 != ('같지 않다') 를 입력한다.
exam.query('math > 50')부등호 >, <, >=, <= 를 이용하면 특정 값 초과, 미만 이상, 이하인 데이터만 추출할 수 있다.
여러 조건을 충족하는 행을 추출하기 위해서 사용할 수 있는 기호는 '&' (그리고) 과 ' | ' (또는) 이다.
exam.query('nclass == 1 & math >= 50')exam.query('math >= 90 | english >= 90')
지정한 목록에 해당하는 행을 추출하기 위해서는 ' | ' 기호를 이용해 여러 조건을 나열한다.
in과 [ ]를 이용해 조건 목록을 입력하면 조금 더 간결하게 작성 가능하다.
in은 변수의 값이 [ ]에 입력한 목록에 해당되는지 확인하는 기능을 한다.
#1, 3, 5반에 해당하면 추출
exam.query('nclass == 1 | nclass == 3 | nclass == 5')
exam.query('nclass in [1, 3, 5]')
문자 변수를 이용해 조건에 맞는 행 추출하기 위해서는 query( )에 전체 조건을 감싸는 따옴표와 추출할 문자를 감싸는 따옴표를 서로 다른 모양으로 입력해야한다.
전체 조건을 감싼 따옴표가 ' ' 였다면, 추출 문자를 감싸는 따옴표는 " " 로 입력해야한다는 것이다.
df = pd.DataFrame({'sex' : ['F', 'M', 'F', 'M'],
'country' : ['Korea', 'China', 'Japan', 'USA']})
dfdf.query('sex == "F" & country == "Korea"')
#실습 QUIZ 풀이 (혼자서 해보기)
#mpg 데이터를 이용해 분석 문제 해결하기
#1. 자동차 배기량에 따라 고속도로 연비가 다른지 알아보려고 한다.
# displ(배기량)이 4 이하인 자동차와 5 이상인 자동차 중 어떤 자동차의 hwy(고속도로 연비) 평균이 더 높은지 구해라.
import pandas as pd
mpg = pd.read_csv('mpg.csv')
mpg_displ4 = mpg.query('displ <= 4')
mpg_displ5 = mpg.query('displ >= 5')
mpg_displ4['hwy'].mean()25.96319018404908
mpg_displ5['hwy'].mean()18.07894736842105
#2. 자동차 제조 회사에 따라 도시 연비가 어떻게 다른지 알아보려고 한다.
#'audi'와 'toyota' 중 어느 manufacturer(자동차 제조 회사)의 cty(도시 연비) 평균이 높은지 구해라.
mpg_audi = mpg.query('manufacturer == "audi"')
mpg_toyota = mpg.query('manufacturer == "toyota"')
mpg_audi['cty'].mean()17.61111111111111
mpg_toyota['cty'].mean()18.529411764705884
# 3. 'chevrolet', 'ford', 'honda' 자동차의 고속도로 연비 평균을 알아보려고 한다. 세 회사의 데이터를 추출한 다음 hwy 전체 평균을 구해라.
mpg_cfh = mpg.query('manufacturer in ["chevrolet", "ford", "honda"]')
mpg_cfh['hwy'].mean()22.50943396226415
필요한 변수만 추출하기
필요한 변수를 추출하기 위해서 [ ] 기호를 이용한다.
exam['english']
변수가 1개만 출력할 경우 출력 결과가 series 자료 구조로 변한다. DataFrame 형태로 출력하고 싶다면 [ ]로 한 번 더 감싸면 된다.
exam[['englsih']]
여러 변수를 출력할 때는 [ ] 안에 다시 [ ] 를 넣어 변수명을 나열한다.
exam[['nclass', 'math', 'english']]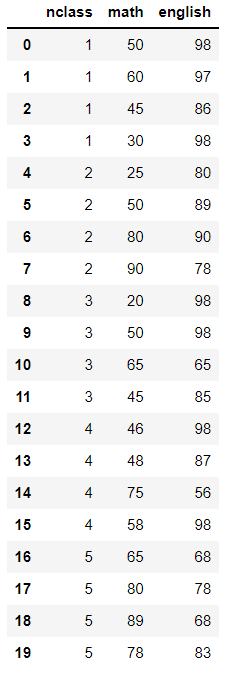
특정 변수만 제외하고 나머지 모든 변수를 출력할 때는 df.drop( )을 이용하면 된다. 제거할 변수명을 columns에 입력한다.
exam.drop(columns = 'math')
여러 변수를 제거하고 싶다면 [ ]에 제거할 변수명을 나열하면 된다.
exam.drop(columns = ['math', 'english'])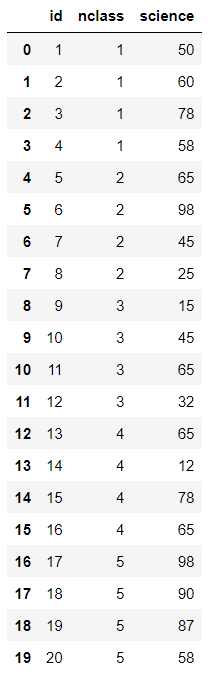
또한, pandas 함수들은 조합항여 함께 사용할 수 있다는 장점이 있다. 함수를 조합하면 코드 길이가 줄어들고 출력 결과를 변수에 할당하고 불러오는 작업을 반복하지 않아도 된다.
query( )와 [ ]
# nclass가 1인 행만 추출한 다음 english 추출
exam.query('nclass == 1')['english']
일부 출력
head( )를 연결해 사용한다. 이는 5행까지 출력하고 괄호 안에 숫자를 입력하면 입력한 숫자만큼 행을 출력한다.
# math가 50 이상인 행만 추출한 다음 id, math 앞부분 5행까지 추출
exam.query('math >= 50')[['id', 'math']].head()
# math가 50 이상인 행만 추출한 다음 id, math 앞부분 10까지 추출
exam.query('math >= 50')[['id, 'math']].head(10)mpg 데이터를 이용해 분석 문제를 해결해 보세요.
# 1. mpg 데이터의 11개 변수 중 일부만 추출해 분석에 활용하려 한다. mpg 데이터에서 category(자동차 종류), cty(도시 연비) 변수를 추출해 새로운 데이터를 만들어라. 새로 만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는지 확인하라.
mpg_new = mpg[['category', 'cty']]
mpg_new.head()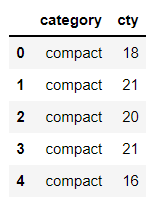
#실습 QUIZ 풀이 (혼자서 해보기)
# 2. 자동차 종류에 따라 도시 연비가 어떻게 다른지 알아보려고 한다. 1번에서 추출한 데이터를 이용해 category(자동차 종류)가 'suv'인 자동차와 'compact'인 자동차 중 어떤 자동차의 cty(도시 연비) 평균이 더 높은지 구해라.
mpg_new.query('category == "suv"')['cty'].mean()13.5
mpg_new.query('category == "compact"')['cty'].mean()20.127659574468087
+) <파이썬에서 사용하는 기호>
| 논리 연산자 | 기능 | 산술 연산자 | 기능 |
| < | 작다 | + | 더하기 |
| <= | 작거나 같다 | - | 빼기 |
| > | 크다 | * | 곱하기 |
| >= | 크거나 같다 | ** | 제곱 |
| == | 같다 | / | 나누기 |
| != | 같지 않다 | // | 나눗셈의 몫 |
| | | 또는 | % | 나눗셈의 나머지 |
| & | 그리고 | ||
| in | 매칭 확인 |
Reference
김영우, 「DO IT! 쉽게 배우는 파이썬 데이터 분석」, 이지스퍼블리싱, 2022, p. 132-150
'Data Analysis > python' 카테고리의 다른 글
| [python] 소상공인시장진흥공단 상가업소정보로 프랜차이즈 입점분석 (2) (1) | 2023.01.25 |
|---|---|
| [python] 소상공인시장진흥공단 상가업소정보로 프랜차이즈 입점분석 (1) (0) | 2023.01.25 |
| [python] 데이터 전처리 ② (0) | 2023.01.14 |
| [python] 데이터 프레임 (1) | 2023.01.08 |
| [python] 변수 생성과 함수 (0) | 2023.01.07 |




댓글